
개요
데이터베이스 테이블 PK 타입 변경에 대한 안건 · Issue #10 · IDLE-Sparta/order-management-server
Content 현재 데이터베이스 테이블의 PK 타입은 varchar, 값은 UUID 입니다. PK 타입을 varchar로 지정한 이유는 추후 PK 생성 방식의 변경을 대비하여 확장성을 고려했기 때문입니다. PK의 타입을 변경하
github.com
주문관리 애플리케이션의 데이터베이스 테이블에 내부식별자와 외부식별자를 분리하는 안건에 대해 고민한 내용을 정리한다.
내부, 외부 식별자의 차이는 다음과 같다.
- 내부 식별자: 애플리케이션 서버 내부, DB 내부에서 사용하는 식별자
- 외부 식별자: 사용자에게 보여지는 식별자
현재 데이터베이스 테이블의 PK 타입은 varchar이며, 값으로 UUID를 사용하고 있다.
내부 식별자를 Bigint 타입의 Auto_Increment 방식, 외부 식별자를 varchar 타입의 UUID 값을 저장하려 한다.
분리의 목적
분리의 궁극적인 목적은 삽입 및 조회 성능 개선과 도메인 데이터 개수 노출을 방지하고자 함이다.
현재 프로젝트의 상황은 다음과 같다.
- 개발 중인 애플리케이션은 조회 기능이 80% 이상이다.
- 조회 시 기본 정렬 조건은 데이터 생성 순이다.
- MySQL 8 버전은 클러스터링 인덱스를 지원한다.
- 현재 데이터베이스 테이블의 PK 타입은
varchar이며, 값으로UUID를 사용하고 있다.
도메인 데이터 개수 노출 방지
Restful API를 설계하면 API url은 보통 다음과 같은 형태를 띈다.
GET /api/v1/post/1
POST /api/v1/post/1
리소스의 식별자 값을 pathvariable로 포함하는 경우가 대부분이다.
해당 식별자가 정수타입의 Auto_Increment 값(순차적 식별자)이라면 아래와 같은 문제가 발생할 수 있다.
- 주문 관리 시스템의 주문 수량이 외부에 노출되면 매출 규모, 고객 수 등을 유추할 수 있다.
- 경쟁사나 외부인이 데이터를 분석해 사업의 성장 추세 또는 운영 현황을 파악할 수 있다.
- 격자가 예측 가능한 식별자를 이용해 불법적인 데이터 접근 시도를 할 수 있다.
따라서 내부 식별자와 외부 식별자 분리로 해결하려 한다.
- 내부 식별자 (Bigint Auto_Increment)
- DB 성능 최적화와 정렬, 조회 성능 개선에 사용.
- 외부에는 노출하지 않고, 내부 로직과 데이터베이스 내 참조용으로만 사용.
- 외부 식별자 (UUID)
- 사용자나 외부 시스템에 비노출성 및 무작위성이 보장된 식별자를 제공.
- UUID는 고유하지만 랜덤 값이기 때문에 데이터 개수나 순서 추적이 불가능하다.
- 이를 통해 보안 강화와 도메인 데이터 노출 방지를 실현할 수 있다.
데이터 삽입 성능 개선 (-)
MySQL 8 버전은 기본적으로 InnoDB 엔진을 사용하며 PK기반 클러스터링 인덱스를 기본 지원한다.
PK가 없는 경우 UK를 기준으로 클러스터링, UK도 없는 경우 내부적으로 클러스터 값을 생성
현재 PK는 varchar 타입의 UUID 값으로 무작위하게 생성된다. 데이터 삽입 시 디스크의 물리적인 위치는 재정렬 되지 않지만, 인덱스는 매번 재정렬되어야 하기에 오버헤드가 발생한다.
고 생각했지만 PK가 각각 varchar, bigint인 테이블에 1000만개의 데이터를 저장한뒤 각각의 삽입 쿼리를 실행해본 결과 거의 동일한 속도를 보여주었다. 평균 (20ms)
데이터 조회 성능 개선 (약 90% 성능 개선)
애플리케이션의 데이터 조회 시 기본 정렬 전략은 생성일 기준 정렬이다.
1000만건의 데이터에서 생성일 기준 정렬 조건으로 조회쿼리가 발생했을 때의 속도를 측정해봤다.
UUID 테이블 (평균 2s 700ms)
created_at 컬럼을 사용하여 생성일 기준으로 정렬한다.
select * from t_promotion
where coupon_id > 1000
order by created_at desc
limit 100
offset 300;
Bigint 테이블 (평균 300ms)
PK를 사용하여 생성일 기준으로 정렬한다.
select * from t_promotion_int
where coupon_id > 1000
order by promotion_id desc
limit 100
offset 300;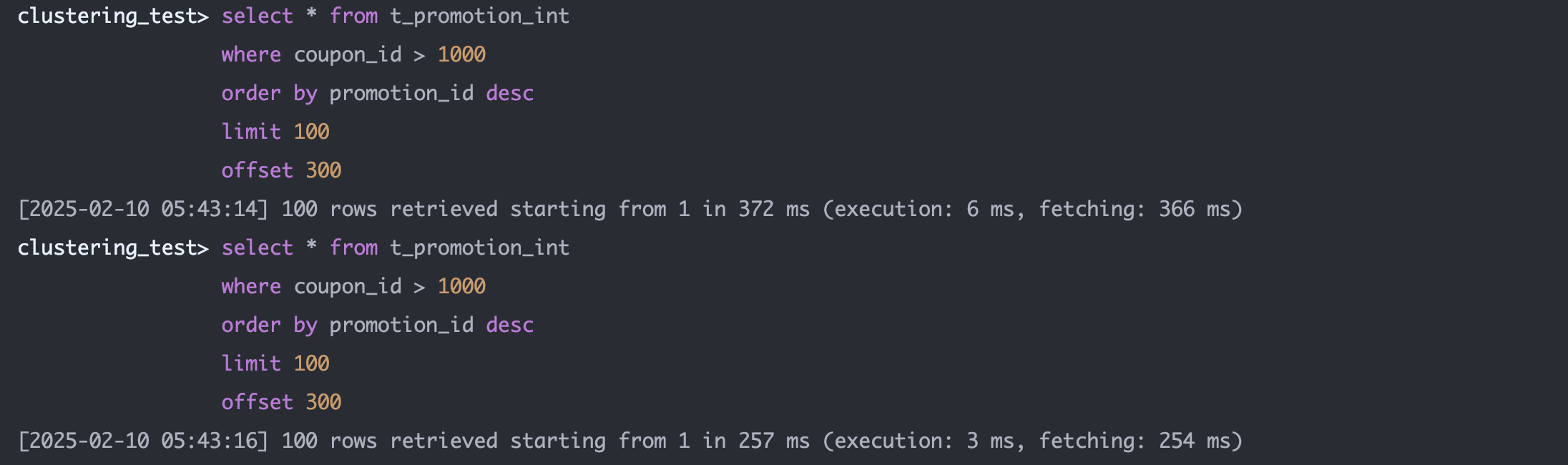
해당 테이블을 정렬 시 PK 인덱스를 사용하기에 훨씬 빠를 수 밖에 없다.

UUID 대비 약 90% 조회 성능 개선이 이루어졌다.
결론
내부 식별자와 외부 식별자 분리: 내부 식별자 (BIGINT AUTO_INCREMENT)는 삽입 및 조회 성능 최적화를 위해 사용하고, 외부 식별자 (UUID)는 데이터 노출 방지와 보안 강화를 위한 식별자로 사용한다.
삽입 성능 차이 없음: BIGINT와 UUID 기반 테이블에 각각 1000만 건의 데이터 삽입 테스트 결과, 삽입 속도는 평균 약 20ms로 큰 차이가 없었다.
조회 성능 약 90% 개선: BIGINT 기반 테이블에서 생성일 기준으로 PK 정렬 조회 시 약 300ms,UUID 기반 테이블은 동일 조건에서 약 2.7초로 조회 성능이 약 90% 개선되었다.
'트러블슈팅' 카테고리의 다른 글
| 템플릿 메소드 패턴으로 관리 포인트 줄이기 (0) | 2025.02.17 |
|---|---|
| 커서 기반 페이지네이션으로 조회 성능 개선 (0) | 2025.02.12 |
| 조건부 속성 문제 해결기 (DDD + Factory Method Pattern) (0) | 2025.01.19 |
| Spring Event - Listener가 이벤트를 인식하지 못하는 문제 (Type Erasure) (0) | 2025.01.16 |
| 이벤트 기반 비동기 통신 구현 및 Kafka를 사용한 이유 (feat. RabbitMQ) (2) | 2024.12.20 |
개요
데이터베이스 테이블 PK 타입 변경에 대한 안건 · Issue #10 · IDLE-Sparta/order-management-server
Content 현재 데이터베이스 테이블의 PK 타입은 varchar, 값은 UUID 입니다. PK 타입을 varchar로 지정한 이유는 추후 PK 생성 방식의 변경을 대비하여 확장성을 고려했기 때문입니다. PK의 타입을 변경하
github.com
주문관리 애플리케이션의 데이터베이스 테이블에 내부식별자와 외부식별자를 분리하는 안건에 대해 고민한 내용을 정리한다.
내부, 외부 식별자의 차이는 다음과 같다.
- 내부 식별자: 애플리케이션 서버 내부, DB 내부에서 사용하는 식별자
- 외부 식별자: 사용자에게 보여지는 식별자
현재 데이터베이스 테이블의 PK 타입은 varchar이며, 값으로 UUID를 사용하고 있다.
내부 식별자를 Bigint 타입의 Auto_Increment 방식, 외부 식별자를 varchar 타입의 UUID 값을 저장하려 한다.
분리의 목적
분리의 궁극적인 목적은 삽입 및 조회 성능 개선과 도메인 데이터 개수 노출을 방지하고자 함이다.
현재 프로젝트의 상황은 다음과 같다.
- 개발 중인 애플리케이션은 조회 기능이 80% 이상이다.
- 조회 시 기본 정렬 조건은 데이터 생성 순이다.
- MySQL 8 버전은 클러스터링 인덱스를 지원한다.
- 현재 데이터베이스 테이블의 PK 타입은
varchar이며, 값으로UUID를 사용하고 있다.
도메인 데이터 개수 노출 방지
Restful API를 설계하면 API url은 보통 다음과 같은 형태를 띈다.
GET /api/v1/post/1
POST /api/v1/post/1
리소스의 식별자 값을 pathvariable로 포함하는 경우가 대부분이다.
해당 식별자가 정수타입의 Auto_Increment 값(순차적 식별자)이라면 아래와 같은 문제가 발생할 수 있다.
- 주문 관리 시스템의 주문 수량이 외부에 노출되면 매출 규모, 고객 수 등을 유추할 수 있다.
- 경쟁사나 외부인이 데이터를 분석해 사업의 성장 추세 또는 운영 현황을 파악할 수 있다.
- 격자가 예측 가능한 식별자를 이용해 불법적인 데이터 접근 시도를 할 수 있다.
따라서 내부 식별자와 외부 식별자 분리로 해결하려 한다.
- 내부 식별자 (Bigint Auto_Increment)
- DB 성능 최적화와 정렬, 조회 성능 개선에 사용.
- 외부에는 노출하지 않고, 내부 로직과 데이터베이스 내 참조용으로만 사용.
- 외부 식별자 (UUID)
- 사용자나 외부 시스템에 비노출성 및 무작위성이 보장된 식별자를 제공.
- UUID는 고유하지만 랜덤 값이기 때문에 데이터 개수나 순서 추적이 불가능하다.
- 이를 통해 보안 강화와 도메인 데이터 노출 방지를 실현할 수 있다.
데이터 삽입 성능 개선 (-)
MySQL 8 버전은 기본적으로 InnoDB 엔진을 사용하며 PK기반 클러스터링 인덱스를 기본 지원한다.
PK가 없는 경우 UK를 기준으로 클러스터링, UK도 없는 경우 내부적으로 클러스터 값을 생성
현재 PK는 varchar 타입의 UUID 값으로 무작위하게 생성된다. 데이터 삽입 시 디스크의 물리적인 위치는 재정렬 되지 않지만, 인덱스는 매번 재정렬되어야 하기에 오버헤드가 발생한다.
고 생각했지만 PK가 각각 varchar, bigint인 테이블에 1000만개의 데이터를 저장한뒤 각각의 삽입 쿼리를 실행해본 결과 거의 동일한 속도를 보여주었다. 평균 (20ms)
데이터 조회 성능 개선 (약 90% 성능 개선)
애플리케이션의 데이터 조회 시 기본 정렬 전략은 생성일 기준 정렬이다.
1000만건의 데이터에서 생성일 기준 정렬 조건으로 조회쿼리가 발생했을 때의 속도를 측정해봤다.
UUID 테이블 (평균 2s 700ms)
created_at 컬럼을 사용하여 생성일 기준으로 정렬한다.
select * from t_promotion
where coupon_id > 1000
order by created_at desc
limit 100
offset 300;
Bigint 테이블 (평균 300ms)
PK를 사용하여 생성일 기준으로 정렬한다.
select * from t_promotion_int
where coupon_id > 1000
order by promotion_id desc
limit 100
offset 300;해당 테이블을 정렬 시 PK 인덱스를 사용하기에 훨씬 빠를 수 밖에 없다.
UUID 대비 약 90% 조회 성능 개선이 이루어졌다.
결론
내부 식별자와 외부 식별자 분리: 내부 식별자 (BIGINT AUTO_INCREMENT)는 삽입 및 조회 성능 최적화를 위해 사용하고, 외부 식별자 (UUID)는 데이터 노출 방지와 보안 강화를 위한 식별자로 사용한다.
삽입 성능 차이 없음: BIGINT와 UUID 기반 테이블에 각각 1000만 건의 데이터 삽입 테스트 결과, 삽입 속도는 평균 약 20ms로 큰 차이가 없었다.
조회 성능 약 90% 개선: BIGINT 기반 테이블에서 생성일 기준으로 PK 정렬 조회 시 약 300ms,UUID 기반 테이블은 동일 조건에서 약 2.7초로 조회 성능이 약 90% 개선되었다.
'트러블슈팅' 카테고리의 다른 글
| 템플릿 메소드 패턴으로 관리 포인트 줄이기 (0) | 2025.02.17 |
|---|---|
| 커서 기반 페이지네이션으로 조회 성능 개선 (0) | 2025.02.12 |
| 조건부 속성 문제 해결기 (DDD + Factory Method Pattern) (0) | 2025.01.19 |
| Spring Event - Listener가 이벤트를 인식하지 못하는 문제 (Type Erasure) (0) | 2025.01.16 |
| 이벤트 기반 비동기 통신 구현 및 Kafka를 사용한 이유 (feat. RabbitMQ) (2) | 2024.12.20 |