
💡 해당 글은 『자바의 신 3판』을 복습하며 도서의 내용과 본인의 주관적인 생각을 정리한 글입니다.
☁️ 내용정리
String
String은 개발하면서 아주 빈번하게 사용되는 객체 중 하나이다.
public final class String
extends Object
implements Serializable, Comparable<String>, CharSequence,
Constable, ConstantDesc // after java 12Object 클래스를 확장하며, Serializable, Comparable<T>, CharSequence 인터페이스를 구현한다.
String 클래스는 final 으로 선언되어 있어 상속받아 확장하는 것이 불가능하다.
String은 보통 아래와 같이 선언한다.
String a = "a";
String b = new String("b");위의 두 가지 선언 방법은 차이가 존재한다. 첫 번째 방법같은 경우는 heap의 a pool of String(이하 StringPool)에 저장된다. 이 공간에 저장되는 String 문자열은 같은 문자열인 경우 캐싱된다. 즉,
String str1 = "a";
String str2 = "a";
boolean result = str1 == str2; // true위와 같은 결과를 가진다. 두 번째 방법은 StringPool영역 밖에 저장된다. 따라서 캐싱되지 않는다. 즉,
String str1 = "a";
String str2 = new String("a");
boolean result = str1 == str2; // false
boolean result = str1.equals(str2) // true위와 같은 결과를 가진다. 특별한 경우가 아닌 이상 첫 번째 방법으로 캐싱하여 사용하는 것이 무분별한 인스턴스를 생성하지 않으므로 좋은 방법이라고 생각한다.
String(byte[] bytes);
String(byte[] bytes, String charSetName);책에서는 바이트 배열을 매개변수로 받는 위의 생성자도 많이 사용된다고 소개한다.
언어 데이터를 바이트 배열 단위로 송신하고 수싱하면서 해당 방식으로 문자열에 담는 것 같다.
String문자열을 byte로 변환하기
getBytes() 메서드를 사용하면 문자열을 byte배열로 받 수 있다. 기본적으로 시스템의 캐릭터 셋을 따라가기 때문에 다른 시스템에서 받은 문자열을 바이트 배열로 변환하는 경우 getBytes(Charset charset) 혹은 getBytes(String charsetName)메서드를 사용하는 것이 안전하다.
charset은 캐릭터 셋이라고 불린다. 알파벳을 제외한 각 나라의 문자는 각자의 고유한 캐릭터 셋을 가지기 때문에 사용하고자 하는 언어에 맞는 캐릭터 셋을 사용해야 정확한 데이터를 표현할 수 있다.
자바에서 한글을 표현할 때, UTF-16을 보편적으로 사용한다고 한다.
내가 사용하는 mac은 UTF-8을 사용하는 것 같다.
regionMatches();
class Main {
public static void main(String[] args) throws Exception {
String text = "This is a book";
// text의 5번째 인덱스부터 비교했을 때, is 의 0 ~ 1 번째 인덱스에 해당하는 문자열과 동일한가?
boolean isMatched = text.regionMatches(5, "is", 0 , 1);
System.out.println(isMatched); // true
// text의 1번째 인덱스부터 비교했을 때, This is 의 1 ~ 4 번째 인덱스에 해당하는 문자열과 동일한가?
// "his ".equals("his ")
isMatched = text.regionMatches(1, "This is", 1, 4);
System.out.println(isMatched); // true
}
}
StringBuilder, StringBuffer
StringBuilder와 StringBuffer는 불변으로 관리되는 String을 보완하기위해 사용한다.
String은 불변으로 관리되며 프로그램에서 생성되는 모든 문자열은 heap에서 관리된다. 만약 반복문에서 하나의 String 변수에 특정 문자열들을 반복적으로 더하기 연산한다고 가정해보자.
String text = "text";
for (int i = 0; i < 5; i++) {
text += String.valueOf(i);
}위의 코드가 동작하면 heap의 String pool에 “text, “1” ~ “5” 의 문자열이 저장되고, 더 이상 사용되지 않으니 unRechable한 객체라고 판단되어 gc에 의해 수거될 것이다. 즉, 불필요한 객체를 heap에 저장하고 수거하는 과정이 발생하기 때문에 성능이 좋다고 생각할 순 없다.
이를 해결하기 위해 StringBuilder, StringBuffer는 append(), insert() 메서드를 제공한다.
StringBuilder, StringBuffer는 AbstractStringBuilder를 확장한다. AbstractStringBuilder는 String과 동일하게 내부적으로 바이트배열 value를 가진다.
두 클래스는 차이는 StringBuffer는 thread-safe 하고, StringBuilder는 그렇지 않다는 점이다.
당연히 성능상으론 thread-safe 하지 않은 StringBuffer가 우수할 것이다.
☁️ 내 생각
new String()
public static void main(String[] args) {
String a = new String("a");
String b = "a";
}위의 코드에서 a == b 는 false 이다. 문자열 차제는 constant pool에 저장하고 캐싱하여 사용하긴 하지만 heap에서 상이한 공간에 저장되기 때문에 이러한 현상이 발생하는 것이다.
실제로 위의 파일을 컴파일하고 바이트코드를 디컴파일해보면
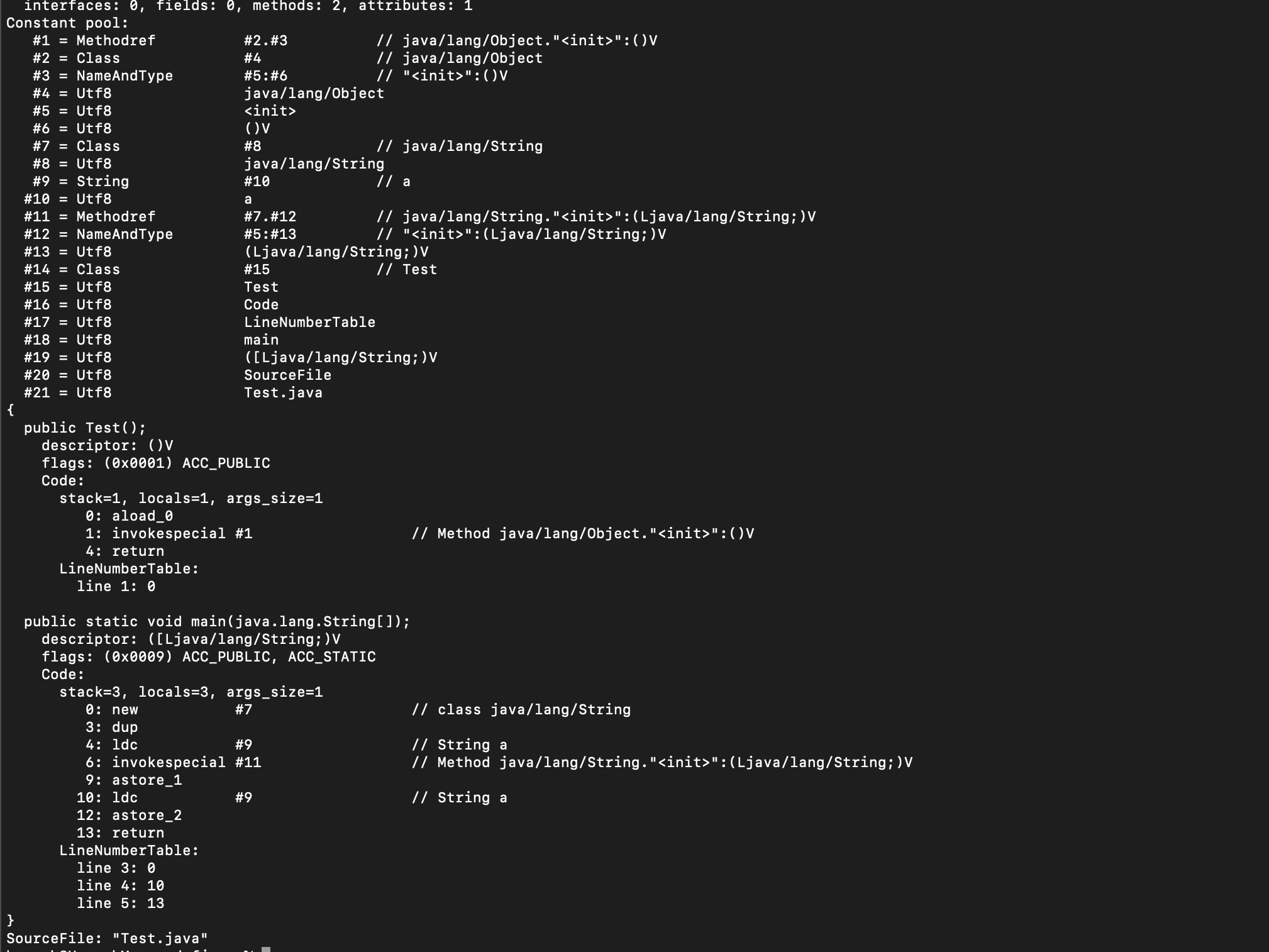
a 라는 문자열을 Constant pool #9에 저장하고 operand stack에서 동일한 #9의 상수를 참조하는 것을 확인할 수 있다.
String 클래스의 intern() 메서드를 보면 아래와 같은 문장을 확인할 수 있다.
A pool of strings, initially empty, is maintained privately by the class
String.When the intern method is invoked, if the pool already contains a string equal to this String object as determined by the [equals(Object)](https://docs.oracle.com/en/java/javase/21/docs/api/java.base/java/lang/String.html#equals(java.lang.Object)) method, then the string from the pool is returned. Otherwise, this String object is added to the pool and a reference to this String object is returned.
https://docs.oracle.com/en/java/javase/21/docs/api/java.base/java/lang/String.html
초기에 string pool은 같은 문자열 자원이 여러번 생성되지 않도록 관리한다.
intern 메서드가 호출되었을 때, 문자열 풀에 메서드를 호출한 문자열과 equals()에 의해 동등한 문자열이 존재한다면 이를 반환하고, 그렇지 않다면 문자열 풀에 해당 문자열을 추가하고 참조를 반환한다.
class Main {
public static void main(String[] args) throws Exception {
String str1 = "a";
String str2 = new String("a");
String str3 = str2.intern();
System.out.println(System.identityHashCode("a"));
System.out.println(System.identityHashCode(str1));
System.out.println(System.identityHashCode(str2));
System.out.println(System.identityHashCode(str3));
}
}888770837
888770837
798154996
888770837객체 고유 주소값을 출력하며 비고해보자. str1 과 “a”는 같은 주소값을 가진다. str2.intern() 또한 스트링 풀에 str2가 가지는 문자열 “a’와 동등한 객체가 존재하기 때문에 스트링 풀의 주소를 가리킨다. 따라서 위의 값들과 동일하다. new String(”a”)는 앞서 언급했던 것처럼 다른 주소 값을 가진다.
문자열 비교와 CharSequence
equals(), equalsIgnoreCase(), compareTo(), compareToIgnoreCase()는 자주사용하는 메서드라 설명을 생략하겠다. contentEquals(CharSequence cs), contentEquals(StringBuffer sb)에 대해 간단하게 짚고 넘어가려 한다.
charSequence
https://docs.oracle.com/en/java/javase/21/docs/api/java.base/java/lang/CharSequence.html
public interface CharSequence {
int length();
char charAt(int index);
CharSequence subSequence(int start, int end);
String toString();
}CharSequence 를 구현한 클래스는 문자 시퀀스에 대한 기능을 제공해야 한다. StringBuilder와 StringBuffer가 그 예시이다. StringBuilder와 Stringbuffer등의 charSequence와의 비교를 위해 존재하는 메서드이다.
replace(), replaceAll()
- replace(char oldChar, char newChar)
- replace(CharSequence target, CharSequence replacement)
- replaceAll(String regex, String replacement)
- replaceFirst(String regex, String replacement)
replaceAll은 내부에서 비교적으로 작업 코스트가 높은 Pattern.comile().matcher() 코드가 수행되기 때문에 특별한 경우가 아니라면 replaceAll 보다는 replace 메서드를 사용하는 것이 좋을 듯 하다.
☁️ 질문
- String, StringBuilder, StringBuffer의 차이는?
- String은 불변으로 관리되며 StringBuilder, StringBuffer는 내부적으로 문자열을 변경할 수 있는 API를 제공한다. StringBuffer에서 구현하는 메서드는 동기화 처리를 지원하여 thread-safe하다, StringBuilder는 thread-safe하지 않다.
- String 대신 StringBuilder, StringBuffer를 사용하는 이유는 무엇인가?
- String은 불변으로 관리되므로 문자열 끼리의 더하기 연산은 String 객체를 3개 생성하고 피연산자 객체 2개에 대한 참조를 끊는다. 참조가 끊긴 객체가 unReachable한 경우 gc에 의해 수거되기 때문에 성능에 영향을 끼칠 수 있다. 해당 문제를 해결하기 위해 사용된다.
예전에 작성한 String 관련 포스팅
2023.04.03 - [JAVA] - [JAVA] String, StringBuilder, StringBuffer
'JAVA > 자바의 신' 카테고리의 다른 글
| 17장. 어노테이션이라는 것도 알아야 한다. (0) | 2024.01.08 |
|---|---|
| 16장. 클래스 안에 클래스가 들어갈 수도 있구나 (0) | 2024.01.07 |
| 13장. 인터페이스와 추상클래스, enum (0) | 2024.01.05 |
| 12장. 모든 클래스의 부모 클래스는 Object에요 (0) | 2024.01.05 |
| 11장. 매번 만들기 귀찮은데 누가 만들어 놓은 거 쓸 수 없나요? (0) | 2024.01.05 |